
What is a data lakehouse?
A data lakehouse is a modern data management architecture that integrates the scalability and flexibility of a data lake with the structured data management of a data warehouse. This unified platform offers both cost-effective storage and advanced analytics in a single system, overcoming the challenge of collecting and managing heterogeneous data across multiple platforms.
Data lakehouses have gained widespread adoption as organizations face growing data volumes and seek efficient, cost-effective solutions to store, manage, and derive value from their information.

Data lakehouses explained
Data lakehouses are an innovative approach to data management that integrate the best features of data lakes and data warehouses. As a unified platform they offer a modernized architecture where you can access and consolidate data across different sources, accelerating time to insight.
A data lakehouse offers specific advantages compared to its predecessors such as:
- Improved governance
- Augmented scalability
- Flexibility in workloads
- Increased data quality and consistency
- Streaming support
Data lakehouse architecture
The architecture of a data lakehouse is typically defined by four distinct layers:
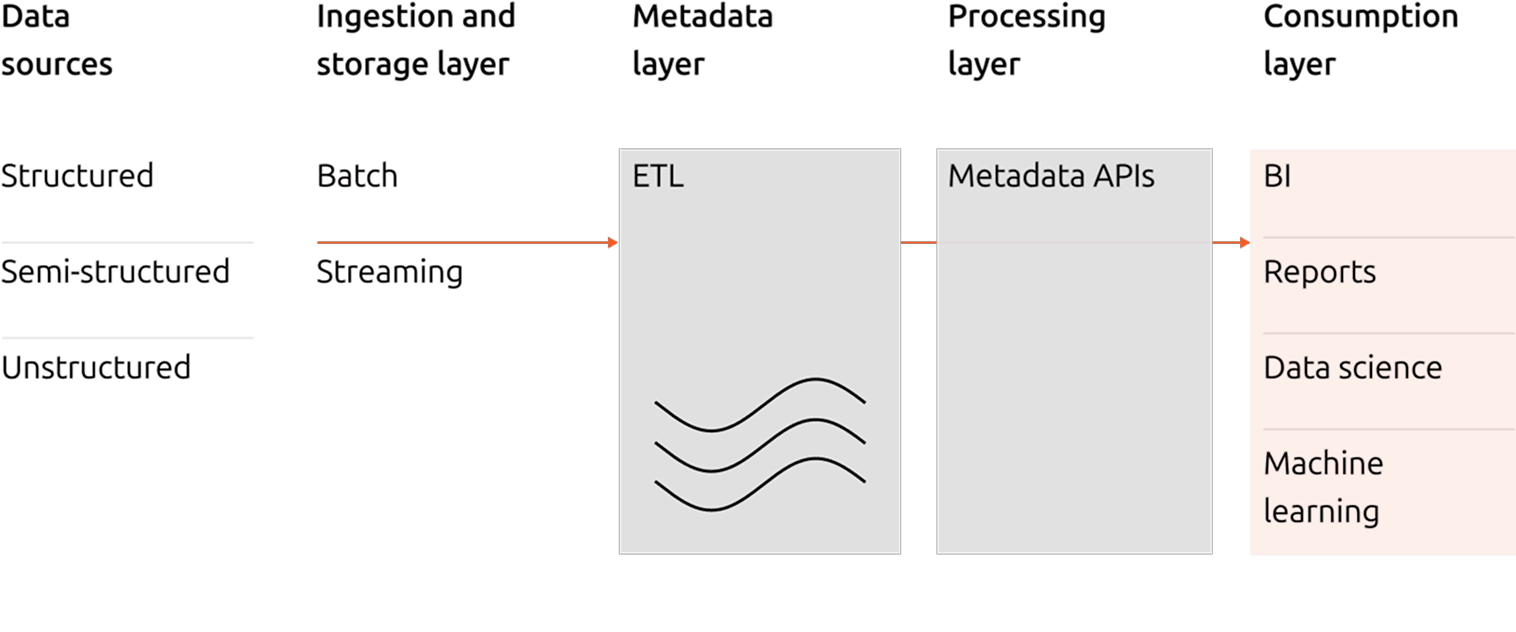
Ingestion
This initial layer consists of acquiring data from various sources, processing it, and converting it into a format suitable for storage and analysis within the lakehouse.
Metadata
The metadata layer is the heart of the data lakehouse, serving as a unified catalog to organize and describe data in its storage.
Processing
Data is cleaned and leveraged for advanced analytics. To perform these tasks, developers will be able to use different languages and libraries to interact with data in a flexible and efficient manner.
Consumption
The final layer of the data lakehouse architecture supports applications and tools, providing access to metadata and stored data.
Data lakehouse vs. data lake
vs. data warehouse
Data lakes, data warehouses, and data lakehouses are distinct data management architectures, each designed to address specific challenges.
| Feature | Data Lake | Data Warehouse | Data Lakehouse |
|---|---|---|---|
| Data format | Stores unprocessed data in its original format. | Stores preprocessed structured data. | Combines both capabilities, allowing heterogeneous data to be stored and processed directly within the environment. |
| Cost effectiveness | Generally cost effective. Avoids the expense associated with structuring data during ingestion, and offers high scalability to handle growing volumes of data. | Tends to be more expensive because of processing requirements, which results in more limited scalability than data lakes. | Balances cost and scalability, offering affordable storage for raw data with advanced analytics capabilities. |
| Use cases | Ideal for exploratory analysis on heterogeneous data. | Optimized for business intelligence. | Enables governance and advanced analytics on different types of data. |
Data lakehouse use cases
Data lakehouses are widely used wherever organizations need a unified platform that combines the scalability of data lakes with the structured querying and governance of data warehouses. Use cases are often found in online retail, financial fraud analysis, advertising and investment. Examples include:
- Predictive maintenance
- Machine learning model optimization
- GenAI
- Market trends analysis
- Fraud detection
- Network intrusion detection and prevention
- Security operations automated response (SOAR)
- Advanced analytics on IoT data
- Illness prediction
Canonical solutions for data lakehouses
Apache Spark®
Canonical offers a sophisticated solution for data lakehouses founded on Apache Spark, Apache Kyuubi and Apache Iceberg — free and open source frameworks for data processing from the Apache Software Foundation.
Canonical's Charmed Spark solution includes containerized images for Apache Spark with up to 10 years of security maintenance and best-in-class support from Canonical, and advanced deployment and operations automation to help you get the most from deploying Apache Spark on Kubernetes.
Apache Kafka®
Canonical offers an advanced solution for deploying and operating Apache Kafka, a free and open source event data processing hub developed by the Apache Software Foundation.
Canonical's Charmed Kafka solution includes support for deploying, configuring, securing, managing, maintaining and monitoring Kafka on cloud VMs or on Kubernetes and includes packages for Apache Kafka maintained by Canonical, with up to 10 years of security maintenance and SLA-backed support available.
Questions? Get answers

Do you have a data lakehouse project in mind and want to get advice on implementing Kafka or Spark? Contact us now to discuss your needs.
Apache®, Apache Kafka, Kafka®, and the Kafka logo are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries.
Apache®, Apache Spark, Spark®, and the Spark logo are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries.